
Improve Search Relevance in AI Applications using Reciprocal Rank Fusion
One of the simplest and most effective techniques for merging multiple search results
Search methods are used to find specific information in a big data set. This information could be in the form of text, images, or speech. In some cases, more than one search technique may be used to find the most relevant information. For instance, you can look for text syntactically by using keywords and also semantically by using embeddings.
When using multiple search methods, each one might score the results differently. For example, one system might give scores from 0 to 1, while another uses a different scale. Combining these results in a useful way is a challenge. Fusion techniques are special methods created to solve this problem.
This article discusses one such fusion technique called Reciprocal Rank Fusion (RRF). RRF combines results from different search systems into a single, more effective ranking. RRF considers the relative position (rank) of each result, rather than their exact scores (which could be in different scales). This allows for a fairer comparison and merging of results from different systems. RRF was introduced in the Reciprocal Rank Fusion research paper. It was shown to perform better than other fusion techniques as measured by the Mean Average Precision (MAP) score. Methods that put the most relevant documents at the top of the list receive a higher MAP score.
This article also covers the use of RRF in various modern AI applications.
Reciprocal Rank Fusion
The formula to calculate the RRF score for an item returned by an individual search is:
RRF = 1/(k + rank)
Where “rank” is the position of the item in the search result and “k” is a constant used to control the influence of top-ranked items. The constant “k” is often set to 60 as explained later.
Here are the steps to merge the results from different searches:
Order and rank items in each search by their absolute score.
Calculate the RRF score for each item in every search result.
Add up the RRF scores for each item.
Make a final ranked list by ordering items by their total RRF scores.
Let’s walk through these steps using an example. Consider two search systems, A and B, used to find books in a collection based on a query.
Step 1: Order and rank items in each search by their absolute score.
For example, let’s say ordering the books by their search scores gives us:
Search-A: [Dune, 1984, Frankenstein, Dracula]
Search-B: [1984, Dracula, Frankenstein, Dune]
Rank the books based on their positions in the above results as shown in this table:
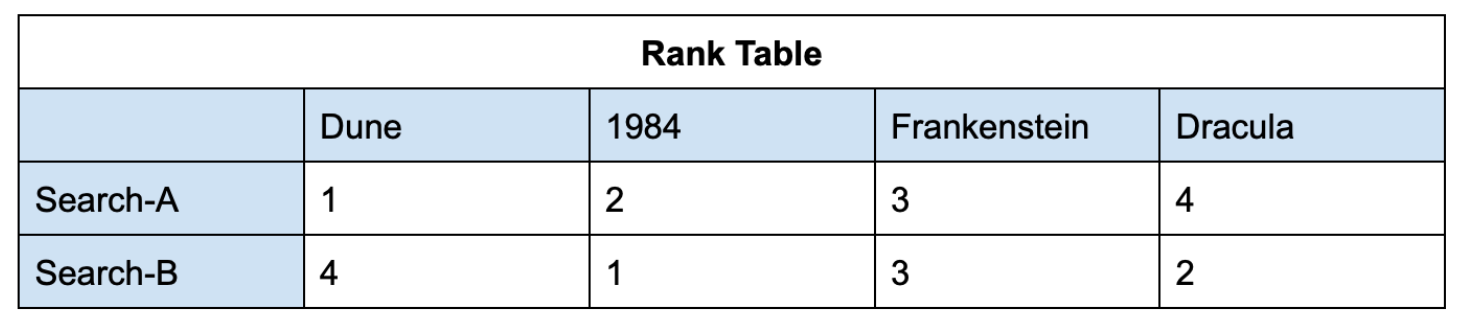
Step 2: Calculate RRF scores.
Calculate RRF score for each book by plugging in their ranks (from the above rank table) into the RRF formula mentioned earlier. Value of k is set to 60.
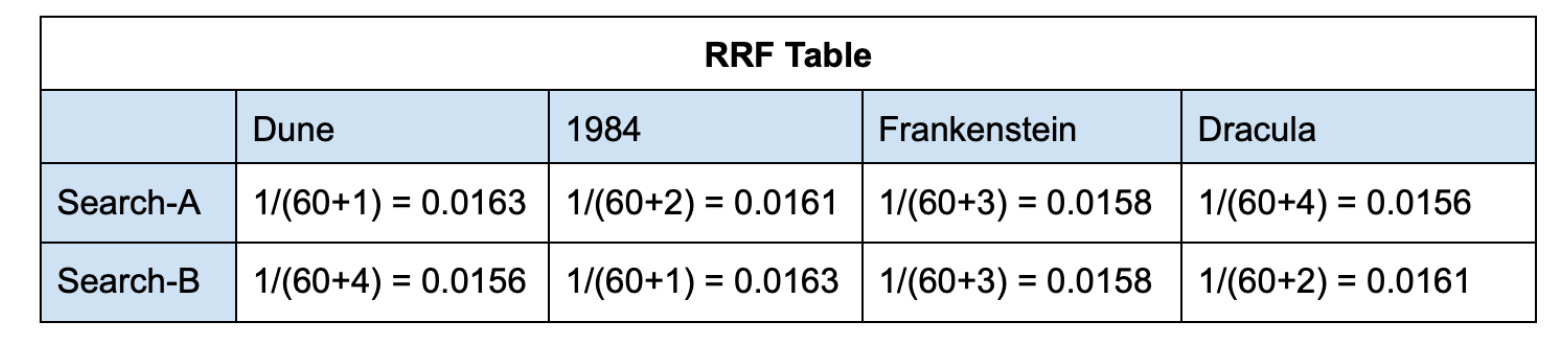
Step 3: Add up the RRF scores for each item.
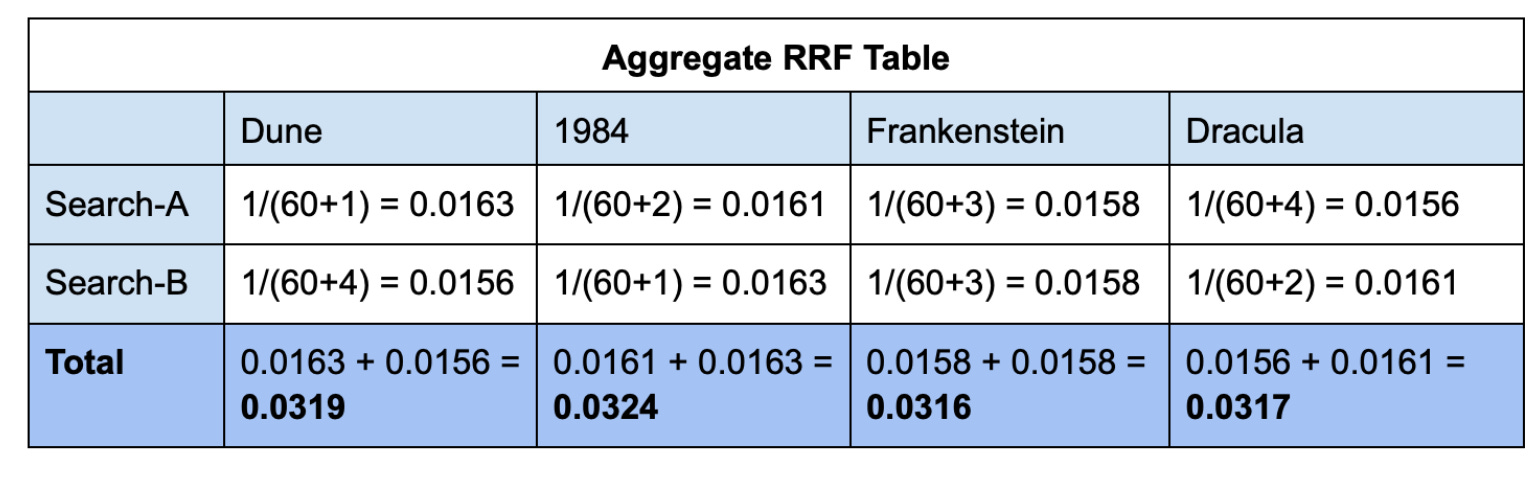
Step 4: Make a final ranked list by ordering items by their total RRF scores.

Higher total RRF score indicates higher relevance, as judged collectively by the various search systems. For instance, even though the book “Dune” was returned at the top by Search-A, it was ranked at the bottom by Search-B. RRF combines perspectives of both Search-A and Search-B resulting in the book “1984”, which was ranked highly by both search systems to be returned at the top in the final result. Combining results in such a fashion potentially leads to more relevant search results.
Purpose of “k” in RRF calculation
The main purpose of k is to adjust the influence of top-ranked items.
For example, say a search places the book "Dracula" first and "Dune" eleventh in the results. The RRF scores for both books using arbitrarily chosen values of k, 9 and 19 are:
RRF score of Dracula (rank 1):
k =19: 1/(19+1) = 0.05
k = 9: 1/(9+1) = 0.1
RRF score of Dune (rank 11):
k =19: 1/(19+11) = 0.03
k = 9: 1/(9+11) = 0.05
In this example, when the value of k is reduced from 19 to 9, the RRF score for the book “Dracula” doubles from 0.05 to 0.1. Meanwhile, the score for “Dune”, an item ranked lower, goes up by only 66%, from 0.03 to 0.05. This shows that reducing k makes the top-ranked items more influential.
Presence of k also ensures that lower-ranked items still contribute meaningfully to the final combined score, though less so than higher-ranked items. For example, without k, the RRF score for the highest ranked item is 1/1 = 1 whereas for an item ranked 11th is 1/11 = 0.09. That is, without k, the lower ranked items are excessively penalized.
The experiments in the Reciprocal Rank Fusion research paper found that a k value of 60 is near optimum.
Applications of RRF
Here are some of the applications of RRF:
RAG-Fusion:
In Retrieval Augmented Generation (RAG), a user’s query is used to find relevant context from a vector database. The retrieved context along with the user’s query is then passed to a large language model (LLM) for a response.
RAG-Fusion improves upon RAG. It tries to bridge the gap between what the user asked and what they intended to ask by translating the user’s question into multiple similar but distinct queries. It performs vector searches using the user’s original question as well as the sibling queries. It merges these search results using RRF and passes them along with all queries to a LLM for an answer.
References: GitHub - rag-fusion and Forget RAG, the Future is RAG-Fusion.
Azure AI Search uses RRF to merge rankings into a single result set whenever two or more queries are executed in parallel. Reference: Relevance scoring in hybrid search using Reciprocal Rank Fusion (RRF)
Elasticsearch provides a RRF API to combine multiple search results. Reference: Elasticsearch Reciprocal Rank Fusion
Summary
In this article, we discussed Reciprocal Rank Fusion (RRF), a simple method for aggregating results from multiple searches. According to the Reciprocal Rank Fusion research paper, RRF outperforms other fusion techniques in delivering more relevant search results. We saw how to calculate RRF with step-by-step instructions and examples. Additionally, we explored RRF's application in modern AI technologies, such as RAG-Fusion.